
人人都是圣斗士,如何做好移动端动作捕捉特效?

人人都是圣斗士
相信很多80后90后的小伙伴心中都藏着一个成为圣斗士的梦,穿上炫酷的圣衣保护雅典娜维护世界和平。
近日腾讯微视上线了“黄金圣斗士换装活动”,通过选择圣斗士相关特效挂件,摆出要求的动作,即可自动识别检测人体躯干及人脸位置,给摄像头中的用户穿上黄金圣斗士铠甲变身。

大家可以在腾讯微视APP中搜索“圣斗士”关键词即可进入活动页面,或者点击首页底部+号进入拍摄界面,也能找到活动入口。上传或拍摄一张正面照片,系统即可自动识别照片姿势,给人物全身换装黄金圣斗士铠甲。可召唤多个星座的圣斗士,如黄金射手座、双子座撒加、处女座沙加等。

虽是小小视频特效,但其中涉及到的CV技术却并不简单,尤其是在手机上实现更是难上加难,本文将解析这一让无数网友实现儿时梦想背后的技术。
如何实现召唤黄金圣衣特效?
召唤黄金圣衣背后的力量,最重要的是运动捕捉(Motion Capture)技术。
其实这一技术已被广泛应用于电影电视制作,在《阿凡达》、《指环王》等好莱坞大片中让人惊艳的特效,枪战游戏中逼真的虚拟效果,以及运动员在体育比赛中的动作分析。

像上图这种依赖于惯性、光学传感器的动作捕捉,技术比较成熟,可以重建出非常精确的人体三维模型信息。但问题也很显然,成本很高,需要把昂贵的传感器安装在捕捉对象的身体上,并且需要高性能的计算设备对采集到的数据在定制的软件中进行处理,才能得到最终的结果。
近年来随着深度学习方法的兴起,使用普通摄像头实现动作捕捉已经渐成现实。
常见的动作捕捉技术在视频特效上的应用,可以划分为如下几类:
人脸2D关键点检测:识别出面部的重要关键点在图像中的2D坐标,通常几十个到上百个。人脸美颜、贴纸等效果都依赖于这一技术。
人体2D关键点检测:识别出人体重要的骨骼关节点的2D坐标,如手腕、手肘、髋关节等,通常十几到几十个。“大长腿”、“瘦腰”等美体效果以及一些体感游戏如“尬舞机”等都建立在这项技术的基础上。
人脸/头 3D Mesh重建:重建出人脸的3D模型,以及投影到2D图像平面上的相机投影矩阵。一般通过几千个顶点组成的网格(Mesh)来描述人脸的3D信息。一些更加具有“立体感”的脸部贴纸、头套以及“捏脸”工具都需要使用这一技术实现。
人体3D关键点检测:在2D人体关键点的基础上,检测出关键点的深度信息。基于这个技术,可以实现对虚拟人物的驱动,玩偶和拍摄对象做同步的姿态。
但要实现“变身黄金圣斗士”效果,上述技术还是不够的,因为需要从普通图像重建出”人体”3D Mesh,将人体的身材用盔甲包裹住,并且要实现在手机上实时运行,这在之前并没有成熟方案。
该技术尚未成熟的主要原因有:
- 缺少大规模高质量的3D数据。人体3D Mesh数据的采集成本非常高,同时由于设备的限制,很难采集到大规模贴合用户手机拍摄场景的数据。
- 人脸近似于“刚体”,可以大概理解为人脸有固定的尺寸,不需要考虑形变等因素。而人体属于“非刚体”,不同的姿态会引起很大的形变,这对视觉技术来讲是挑战很大。
- 人脸有相对固定的“特征点”,如眉梢、嘴角等部位,非常的明显。而人体缺乏这样稳定的特征点,并且拍摄时衣着的变化很大。
- 人体的深度信息会随着不同的姿态发生很大的变化。而从二维图像恢复出三维空间信息本身有很多组解,需要非常多的依赖于“先验信息”,才能推测出合理的解,而更多的变化就意味着更难去得到有效的“先验信息”。
- 不同人的体型变化很大,而穿上不同厚度和材质的衣服又对体型的估计增加了难度。
- 重建出人体Mesh需要同时实现人体检测、人体2D/3D关节点检测、人体体型检测、人体姿态和关节旋转检测以及相机投影矩阵回归等多个任务。同时,在手机端计算资源极其有限的情况下,同时完成好上述多个任务面临非常大的挑战。
尽管面对诸多挑战,但腾讯微视发布器团队有效的解决了上述问题,实现了开篇那些炫酷变身特效,速度也很不错,在中高端手机上,人体3D重建部分可以达到~90 FPS的处理速度。
整体技术实现方案
高质量的数据采集和优秀的算法方案设计同样重要。
巧妇难为无米之炊,首先要解决的是要获取高质量的3D人体Mesh重建数据。
一、数据采集
1)低成本数据采集系统
为此,微视发布器团队搭建了一套动捕系统,并基于此开发了相应的Mesh重建算法,可高效率的进行训练数据的迭代,解决更多场景和姿态下的问题,增强模型的泛化性能。
综合考虑到重建精度、采集速度以及成本等方面的因素,采用了一种相对较低成本的硬件方案来搭建:3台AzureKinect,3台三脚架,数据同步线,USB延长线以及Windows电脑一台。

2)简易相机标定
标定即计算各个相机的相对位置和姿态,方便后续对多数据源的数据进行融合。微视发布器团队实现了一种自动化的操作简单的标定方法,只需要像下图中的帅哥这样抱着棋盘格箱子,在场景中转一圈,就可以计算出3台相机之间的相对位置和姿态,耗时仅需1分钟。

3)高标准数据采集与处理
首先借助AzureKinect提供的Collaboration功能将三台相机的视频流做同步处理,然后采集RGBD、深度人体Mask、人体3D关键点信息并保存下来。

第三步对每一台深度摄像机生成对应的点云数据,根据相机标定的结果,将三台相机的点云数据进行合成,最终得到统一坐标系下的3D点云数据。
最后,将获取到的原始数据合成为训练模型所需要的Mesh参数。这一步主要基于Fitting优化的方法,通过对人体的Pose、Shape等参数进行调整迭代,尽量降低重建后人体与3D点云数据之间的误差。采用3D点位之间的欧式距离(MPJPE)衡量重建效果,整体控制在20mm内。

二、整体算法框架
实现人体3D Mesh重建涉及到比较多的相关技术,先来看一张框架图,大概描述了需要做哪些技术积累以及生成人体3D Mesh的方法:

先将视频拆分成一帧帧的图片,从每张图片中找到人体所在的区域,然后计算出人体的2D关键点信息,接着结合前后帧的时序信息估计出关键点的深度即得到人体的3D关键点坐标。然后结合2D/3D以及图像信息估计出人的体型和3D姿态,从而获得人体在模型坐标系下的3DMesh和相机的投影矩阵。微视发布器团队使用7千多个顶点和1.5万的面片,重建出图像坐标系下的人体3D Mesh;另外从图像中重建出的Mesh需要经过滤波处理去掉抖动,这样就得到了视频中的人体Mesh。渲染引擎根据这些信息给视频中的人物“穿上”盔甲。
下面介绍用到的单点技术。
1)人体检测
首先要逐帧的检测出人体在图片中的位置,并且将该区域截取出来送给人体2D骨骼关键点检测模块。目前常见的检测框架可以按照one-stage, two-stage, anchor-based, anchor-free来划分。其中精度更高的主要是two-stage的框架,比如代表的工作有Faster-RCNN等,但由于采用了RPN来生成大量的候选框,所以速度会比较慢。
One-stage相比于two-stage模型由于没有RPN模块所以速度更快,在工业界得到了更广泛的使用。但与此同时会带来精度上的损失,代表工作包括SSD,YOLO,RetinaNet等。以上的工作都需要anchor的辅助,而从18年开始涌现出了很多anchor-free的方法。这类方法不再使用anchor提取候选框,通常来讲可以做到更快的检测速度,代表的工作包括CornetNet,CenterNet,FCOS等。
2)人体2D关键点检测
当前业界通常采用的人体关键点检测框架包括两大类:Top-Down和Bottom-Up。基于Top-Down的方案,需要先进行人体检测,得到人体的在图像上的区域后,再对人体区域进行分析,得到人体骨骼关键点,代表的工作有Mask-RCNN。他的优势在于能够做到更高的检测精度,但由于需要依赖于强有力的检测器,所以需要同时需要人体最小外接矩形框和人体骨骼关键点两部分的标注数据。
此外,在多人场景中,由于每一个检测框都需要独立进行一次关键点检测,时间开销会更大。另一种方案是以open-pose为代表的Bottom-Up方案。这类方法先检测图片中所有关键点的位置,然后通过后处理将同一个人的关键点聚合在一起。这种方案相比于Top-Down在多人场景下具有更加稳定的时间开销,速度更快,但检测精度往往不如Top-Down并且后处理实现难度相对更大。
3)人体3D关键点检测
有了2D关键点,下面就是需要估计出这些2D点的深度信息,从而得到关键点在三维空间中的坐标。假设求解的3D坐标为X,已知2D坐标A,相机投影矩阵C,则它们之间的关系可以简单表达为:
A = CX
这个公式可以理解为3D坐标X经过某种投影方式C,投影到2D平面上得到了2D关键点坐标矩阵A。在这个问题中A已知,需要求解C和X,通常这类问题没有唯一解。这就好像是已知一个数字20,需要找到几乘以几能够得到20,答案可以有无数组解:(20/3)*3=20, 4*5=20, 6*(20/6)=20。但是,在这无数组解当中,仅有少量的解会让人视觉上产生“合理的”感觉,需要给这个方程增加约束条件,得到合理的3D坐标和投影矩阵。
人体本身的物理结构(某些姿态正常人是无法做出来的),动作序列中就包含了这些约束,当前很多在这方面SOTA的工作就是采用了这样的约束:如Facebook在CVPR2019年的“3D human pose estimation in video with temporal convolutions and semi-supervised training”工作主要是用视频动作序列来实现深度信息的估计。还有一些工作如“3D Human Pose Estimation in the Wild by Adversarial Learning“, 通过GAN对模型预测出的动作是否符合“正常人的动作”来约束3D估计结果。由于数据的获取难度大,数据本身缺乏,目前更多的工作采用半监督的方式,增加对2D关键点标注数据的利用来提高模型的效果。
相机投影矩阵主要指从模型坐标系投影到图像坐标系的变换矩阵,在现实世界中的主要由相机的内参和外参来决定。如果已知了图像中人体2D关键点坐标以及3D坐标,就可以通过pespective-n-point等迭代方式来估计出相机的投影矩阵。
2D/3D姿态检测部分的效果如下图所示:

4)人体3D Mesh
获得了2D/3D关键点信息后,如果要恢复出人体的Mesh,还需要估计两个重要的信息,就是人的体型以及关节的3D旋转。人体的体型简单讲就是人的高矮胖瘦,虽然关键点能提供一部分的身材信息,但仅依靠关键点很难准确的恢复出身材,特别是胖瘦。3D关键点虽然包含了部分的关节夹角信息,但关节还需要包含更多的自由度,特别是旋转。
从技术方案的角度上讲,人体3DMesh重建主要分成 Deep Learning和Fitting两种方案。基于Fitting的方法一般基于已有的人体模型,如SMPL/MANO等,通过最小化人体模型投影到图像上的点与已知人体关键点的误差,得到每张图片的最优模型参数。基于Fitting方法的优势在于能够得到高精度的人体Mesh,一些公开数据集如:3DPW等都采用这种方法构建数据。
但这种方法的弱点也很明显,首先是速度太慢,每张图片都需要迭代至少几十到上百次,一张图片的处理往往需要一到几分钟。此外,考虑到体型问题,一些方案直接采用3D扫描仪事先扫描出人体,大大提升了数据采集的成本。基于Deep Learning的多数方法同样需要依赖于人体模型,通过神经网络估计出人体模型的参数,代表性工作如VIBE,这类算法通常称为model-based的方法。
这类方法有两方面的问题,首先可获取到的数据很少而且拍摄环境局现在实验室中,虽然一些工作如Surreal,Human3.6使用CG制作虚拟的in wild场景,但这样的数据跟真实的数据仍然有比较大的差距。第二,前面提到关节的3D旋转很难通过图像去估计。相比于model-based方案,model-free方案提供了另外一种思路,这种方法是直接回归人体mesh上的密集3D点坐标,并通过在loss中增加人体shape、pose等先验信息进行约束。
相关的工作主要依赖于图神经网络来建模人体不同关节点之间的拓扑结构。代表工作如:“Pose2Mesh: Graph Convolutional Network for 3D Human Pose and Mesh Recovery from a 2D Human Pose”等。
3D Mesh效果展示如下图所示:

基于上述算法设计,可实现稳定、快速的人体Mesh 重建,据悉,这是国内首次在移动端部署人体动作捕捉技术,通过手机即可通过人体捕捉技术让视频特效流畅运行。
从模型到工程的全方位优化
一、动作捕捉算法优化
经过上述的基础技术储备后,就需要可以开始移动端实现的工作了。微视发布器团队主要从数据集制作、算法流程改进、网络结构搜索、移动端工程优化以及算法细节打磨等几个方面对算法进行了优化。
构建大规模贴近用户使用场景的高质量数据集是解决问题的基础和关键。因此,在数据集制作方面,采集了上万个贴近手机端用户拍摄内容的视频数据,从中抽取了几十万张视频帧图片。然后,对这些图片进行2D关键点标注,并采用上一节中提到的一系列算法进行处理,得到了初步的3D Mesh数据。然后,对这些数据进行清洗,从贴合度表现、3D合理性等多个方面对每一张图片进行评估,去掉效果比较差的图片,得到了最终用于训练和评估的3D人体Mesh数据集。
接下来进行移动端的实现和优化。首先在移动端实现了人体检测/跟踪,2D关键点检测,3D姿态估计,相机投影矩阵估计,3D Mesh重建整套技术的流程,第一版的移动端3D Mesh出炉了。但现在问题来了,这么多的流程,实现单帧图像15ms以内的处理速度非常的困难。于是从三个方面进行了改进:
1. 网络Backbone结构的设计与优化
结合HRNet、MobileNet系列网络等不同结构的优势,在大规模的数据上进行了不同结构设计的探索和调参,针对不同计算能力的手机做针对性的设计,保证对不同的机型在速度和效果上达到最佳的平衡。
2. 算法流程改进
对整个的算法串行的流程进行优化,整个人体检测、2D关键点、3D关键点、人体Mesh、相机姿态估计全部调整为并行实现,极大的提升了算法整体的效率。
3. 移动端工程优化
基于腾讯优图团队提供的TNN移动端深度推理框架,实现了移动端模型的高效推理。对于特定的算子和矩阵运算,与优图TNN团队合作进行了针对性的底层优化,保证算法的高效运行。同时,对于模型的后处理也进行了算法层面的优化,在保证不使用影响体验的精度损失上获得了更极致的运行效率。
经过上述一系列的优化后,终于能够得到一个效果稍微像样一点的Demo了,但这还不够,追求极致的脚步从未停止!针对不同的拍摄光照、人体的姿态、不同的体型、衣着、拍摄距离、拍摄角度以及不同拍摄背景中发现的Bad Case,从训练方式、参数调整、Loss函数设计、数据更新与优化等方面进行了更多深度的研究,解决了贴合度、检测稳定性等多方面拍摄中的常见问题。同时,进一步压缩了模型计算开销,将单帧的总体处理时长从15ms优化到了当前的11ms。
二、特效渲染优化
微视发布器技术团队基于重建的人体 3D Mesh 量身定制了一套AttachToBody的渲染方案:
- 能够保证服装模型在三维世界和二维图像上位置和旋转正确,贴合人体表面;
- 能够提供PBR(基于物理的渲染)每个环节需要的正确信息,确保高质量的渲染效果。
同时为了项目需要,技术团队在原有引擎基础上开发了自定义材质系统,为玩法提供了更自由灵活的材质与光照解决方案。借助于强大的流程控制和脚本系统,技术团队很好的将人体重建,服饰真实感渲染,骨骼动画,转场特效等要素串联在一起,提供了完整流畅的视效表达。此外,部分机型上启用了IBL, SSAO等技术来提升整体的光影效果。
在性能方面,为了提升效果整体的覆盖率,在低端机上采取了Material Capture材质捕捉技术方案,用较小的计算成本拟合出近似PBR的真实感效果。同时在一些高频且量大的矩阵计算中启用了NEON加速方案,整体降低了数学计算耗时。
三、视觉效果优化
在细节打磨和工具支持方面,依托Light Studio对3D场景强大的编辑和可视化能力,以编辑器组件的方式提供给设计同学完整的工具链支持,包括对衣服SRT数据的精准调整,对环境光/衣服材质主要参数的可视调整等。通过设计同学,算法同学和特效同学多轮的效果打磨,在衣服贴合度与跟随性,身体比例协调性,衣服视效等方面均有明显的提升。
在细节打磨和工具支持方面,依托Light Studio对3D场景强大的编辑和可视化能力,以编辑器组件的方式提供给设计同学完整的工具链支持,包括对衣服SRT数据的精准调整,对环境光/衣服材质主要参数的可视调整等。
设计团队为达到高品质质量,与技术团队深入协作,提供优化方案:
- 明确直观的预期效果,明确优化方向,给出优化建议;
- 辅助优化引擎渲染能力,使最终效果更接近设计师预期;
设计师通过对微视引擎的了解,设计出高标准且不超纲的设计,同时团队内的TA同学与技术团队在引擎内实现高品质视觉效果。遇到瓶颈时,与算法和技术团队及时沟通调整技术或设计方案。
同时在打磨阶段更是与技术团队强绑定,最终达到较高标准的效果质量。
预期效果:

引擎实现:
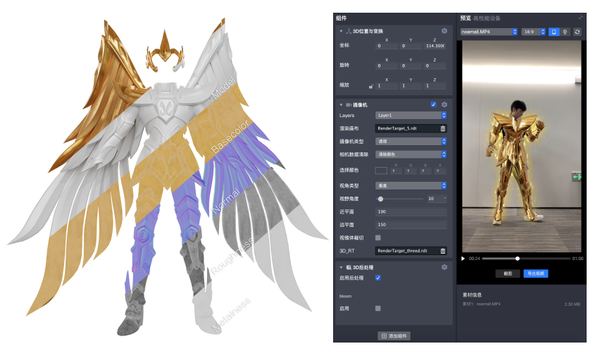
通过设计团队、算法团队和特效团队多轮的效果打磨,黄金圣斗士的铠甲在衣服贴合度与跟随性,身体比例协调性,衣服视效等方面均有明显的提升。
团队介绍
OVBU拍摄算法团队:
致力于视频业务场景下内容生产、制作和发布相关的技术创新研发,以技术赋能创作者。汇聚了一批行业内顶尖的算法专家和产品经验丰富的研究员和工程师,拥有丰富的业务场景,持续探索前沿AI、CV和CG算法在内容生产和消费领域的应用和落地。
团队持续招聘中,请联系: quenslincai@tencent.com
应用研究中心:
平台与内容事业群(PCG)应用研究中心(Applied Research Center,ARC)作为PCG的侦察兵和特种兵,肩负着探索和挑战智能媒体相关前沿技术的使命,旨在成为世界一流应用研究中心和行业标杆,聚焦于音视频内容的生成、增强、检索和理解等方向。
团队持续招聘中,请联系: jonytang@tencent.com
光流产品中心:
围绕短视频拍摄与编辑业务场景,在图形特效,音视频编辑,美颜美妆,人脸/AR等相关玩法上有丰富的技术积累,并落地在微视,手机QQ,微信等产品中。团队未来将持续在2D/3D渲染,创作者工具,创意特效玩法,图形新能力等方向进行技术投入,致力于打造行业一流的短视频发布器一体化解决方案。
团队持续招聘中,请联系: quenslincai@tencent.com
MXD创意平台设计中心:
拥有拍摄与视频编辑相关内业顶尖创意设计师,在创意拍摄玩法、视频特效、3D美术、美颜美妆、视频后编辑等相关有丰富的经验,服务于服务于腾讯在线视频BU。团队未来将继续研究拍摄趋势与视觉创新,发掘新潮的创意特效,致力于给用户带来更优质的创意玩法。
团队持续招聘中,请联系: quenslincai@tencent.com