
OPPO 数字人语音驱动面部技术实践
导读:本文将介绍数字人语音驱动面部技术与 OPPO 小布助手实践。主要围绕以下几个部分展开:
- 数字人驱动技术概览
- 数字人语音驱动面部算法
- 小布业务的算法落地实践
- 领域现状与待解决的问题
小布助手是国内首个月活破亿的智能助手。从 2018 年 12 月发布以来,截至目前累计覆盖 3 亿设备,每月活跃用户近 1.4 亿,月均交互次数 30 亿次。
小布助手是 OPPO、OnePlus、Realme 智能手机和 IoT 设备的内置AI 助手,包含语音、建议、指令、识屏和扫一扫五大能力模块,为数亿用户提供多设备、跨平台、多场景的服务。

2019 年,小布助手上线了虚拟人布美美,成为业界首个基于数字人多模态交互的手机智能助手。同时围绕数字人,小布也打造了自己的数字人开放平台。目前平台整合了算法、工程、基础设施等多项能力,赋能了小布的多个应用场景。
分享嘉宾|唐涔轩 OPPO小布助手 高级算法工程师
编辑整理|田育珍 搜狗
出品平台|DataFunSummit
01/数字人驱动技术概览

接下来介绍一下数字人主流的驱动技术:
- 动捕驱动:通常需要在人体关键位置(如:手指、关节)等位置佩戴专业的追踪设备,进行骨骼绑定,并结合面部关键点或 Apple ARkit 进行面部表情捕捉,最后进行实时推流。驱动的时候依赖真人的输出。右侧的图片是使用动捕驱动二次元形象跳舞的例子,可以看到,真人身上绑了很多传感器,这种驱动方式硬件成本较高。后面的几根杆子是定位用的激光雷达,一般需要用到三个或以上,普通的用户很少涉及动捕设备进行驱动。
- 语音驱动:基于音频特征控制面部、口型、身体驱动画面;该过程主要包含音频特征提取和音频特征与面部表情、身体动作响应。同时依赖语义理解、ASR、TTS、情感分析和知识图谱等技术的支撑。
- 关键点驱动:基于普通的 RGB 摄像头捕捉人体运动、人脸表情,以驱动模型实时运动。目前主要用于直播平台,如:B 站、YY 等。驱动时依赖真人的输出。这种技术很依赖关键点的定位精度,但成本非常低廉,用户只需要利用自己的 PC 的前置摄像头就可以实现虚拟形象的驱动。
还有一些其它的驱动方式,如:手语驱动,这里就不一一介绍了。从上面三种驱动方式可以看出,动捕驱动和关键点驱动是需要真人的,更多还是一种一对多的内容呈现方式。但作为智能助手,个性化需求需要多对多的场景。语音驱动和智能助手交互的沟通方式更加契合的,今天主要围绕语音驱动进行讲解。
--
02/数字人语音驱动面部算法

下面介绍一些语音驱动面部算法,包括:基于传统音素分析驱动、生成式驱动、BlendShape 驱动、Mesh 的驱动算法。

基于传统音素的分析方法中,较常用的方式是提取共振峰。这种方式的特点有两个:
(1)算法实现简单,计算复杂度低
(2)驱动音素 BlendShape 时需要复杂的后处理,比如时间戳的对齐
它是ASR领域的一个经典方法,在数字人领域与 BlendShape 结合后又重获新生。

随着深度学习的发展,尤其是生成对抗网络的发展,慢慢出现了基于生成式的口型动画生成算法。最经典的是 Wav2Lip, 通过音频和目标视频,基于生成对抗网络生成音频对应的口型视频。这种方法的后续变种和改进目前广泛应用于客服机器人,例如银行柜台的客服机器人。它们的主要特点是以真人的形象展示,借助 Wav2Lip 这类算法根据音频生成嘴部相应的口型动画。

接下来就是基于 BlendShape 的驱动。这篇论文是网易 2019 年提出的,通过深度学习网络对 BlendShape 权重系数进行预测,也是通过深度学习预测 BlendShape 权重系数的代表作。游戏公司在做数字人驱动有天然的算法、数据和美术资源的优势,像网易、腾讯数字人业务。

这是英伟达 2017 年的一篇论文,它在当时是非常前沿的。它不是去拟合 BlendShape 权重系数,而是直接预测面部 3D 关键点的位移,同时模型引入了情绪的编码。从图中可以看到,网络中的模块包含传统音素分析方法中的共振峰分析模块。
英伟达从 2017 年开始持续对该算法进行了改进和优化,目前应用于Omniverse 的 Audio2face 模块。Omniverse 可能大家都很熟悉,它的英文驱动效果还是蛮惊艳的。它主要的核心就是这个算法,也在不断地做改进。
--
03/小布业务的算法落地实践

前面讲了一些数字人驱动在不同驱动方式的代表作。小布在数字人驱动领域是一个追赶者,但也有一些独有优势。
首先,数字人驱动是面向业务落地的,小布团队从去年开始到现在持续投入了大量的资源,相继购买了惯性动捕设备和 4D 面部采集设备以支持小布数字人的研发工作。此外,小布有海量的文本和 Audio 数据,特别是唱歌领域。小布背靠 OPPO 音乐,积累了百万量级的大规模音乐人声预训练模型。
接下来围绕小布的端侧 Audio2Lip、云侧 Audio2Lip、端侧 Sing2Lip、仿真头模 Mesh 驱动、仿真头模 Sing2Mesh、Mesh2BlendShape 相关的进展讲一下小布业务的落地实践。

目前小布线上落地的形象有小布和布美美,从右侧的图片可以看出,小布是卡通形象,布美美是拟人形象,它们都具备云端和端侧的驱动能力。布美美的 BlendShape 更多样化,它的实时性在 40fps;小布 BlendShape 更简单,实时性在 60fps。对比端侧受限于算力的限制,云侧的驱动精度都更高。小布端侧 Audio2Lip 精度为 92%,布美美为 90%。小布云端 Audio2Lip 精度为 97%,布美美为 95%。这两个形象目前都具备唱歌的能力。

小布助手作为智能终端厂商预置的智能助手,我们更希望数字人部署到端侧,这样可以节省大量的网络带宽和用户的流量。因此小布一直致力于端侧的驱动和端侧渲染算法的研发。小布的端侧算法大概如下:
(1)基于传统的音素分析算法,实现特征端侧计算
(2)结合小布线上音色库进行了针对性特征库构建
(3)音素 BlendShape 通过自适应参数实现端侧实时驱动

这是小布端侧 Audio2Lip 的演示。使用 OPPO 手机对小布助手说“进入小布空间”,可以体验与小布形象互动。
以上是 Audio2Lip 在端侧的演示。左边是一些性能指标:这个模型渲染、驱动都在端侧,唇形精度 92%,60fps,渲染引擎基于 Unity,舌头和牙齿都是独立的 BlendShape 驱动的。
端侧部署时,功耗和内存限制模型的大小,降低部分模型的精度。这也是功耗与性能的折衷。

除了端侧的算法,小布也有自己的云侧 Audio2Lip 的算法。云侧算法有以下几点:
(1)使用了 DL 模型进行音频特征分析,并抽取了元音预测结果;
(2)对音素 BlendShape 基于 ASR 音素时间轴进行了对齐
(3)使用了自适应网络进行特征融合后输出 BlendShape 系数
从图中可以知道这个模型使用了 wav2vec 2.0 进行音频特征的抽取。唇形的精度在小布形象可以达到 97% 左右。这个模型也适用于布美美的形象,准确率在 95% 左右。

数字人唱歌也是非常重要的场景。目前在中文领域,Sing2Lip 数字人做的比较好的是微软小冰。
左图是人说话时元音和嘴型对应的关系。右图是人唱歌时母音发音的规范。仔细研究的话,会发现人说话和唱歌发音大部分嘴唇、口腔的震动是相似的。两者区别最大的是唱歌时有延音和颤音,同时唱歌还有真声和假声切换的场景。例如周杰伦的《霍元甲》就有真声和假声。我们和一些歌手聊过,真声和假声切换对他们自身的音乐素养要求还是蛮高的,这也是 Sing2Lip 在数字人唱歌领域非常难处理的地方。

小布 Sing2Lip 采用的是端侧驱动和端侧渲染:
(1)对音乐人声使用了流派识别,用于优化不同流派下歌曲的效果。
(2)对音乐人声进行基于传统算法的旋律、节奏和音高分析。在 2019年的时候,早稻田大学的研究者做了 Sing2Lip 的研究,认为旋律、节奏、音高属于副语音学,在 Sing2Lip 中有重要的作用。我们也沿用了他们的方式,把旋律、节奏和音高特征作为参考。
(3)使用了音乐母音分类并结合其他特征进行数据对比,我们构建了一个音乐母音的数据库,和音素的 BlendShape 进行融合,并生成 BlendShape 权重系数。

下面是 Sing2Lip 目前的演示。
左边是 Sing2Lip 性能的参数。小布 Sing2Lip 目前已经适配了主要音乐流派。刚演示的是中文 Rap,小布在 Rap、流行和民谣中都有很好的效果。同时,我们结合音乐人声的训练模型适配了各种语言,中文、英文、粤语都是可以覆盖的。
通过研究我们发现:通过基于歌手的各个音调的母音音素分析,能达到高精度的音素化 BlendShape 的驱动。
前面提到的更多的是基于 BlendShape 的驱动。近些年,基于 Mesh驱动的研究也慢慢多起来。
BlendShape 驱动的特点是很多 BlendShape 需要美工通过工具或软件手工捏出来。BlendShape 驱动的效果一部分受算法的影响,还有一部分受美工水平的影响。大家也都知道,只要涉及艺术的,收费都比较贵。基于成本的考虑,基于Mesh的驱动也慢慢在数字人领域越来越重要。
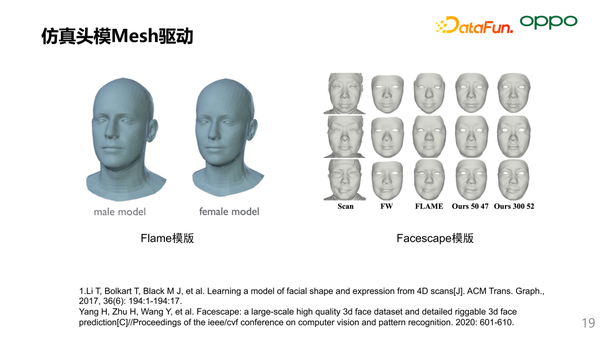
提到 Mesh 要先说到开源的头模,这里主要有两个头模:Flame 是基于欧美模特构建,Facescape 是国内南京大学开源的,基于国内模特构建。这两个头模的差异在顶点数、面片数和模特群体的选择。作为一个智能助手,我们不光要考虑的渲染的效果也要考虑性能,我们选择了 Flame 头模作为主要研发的参考头模。因为点数和面数对性能功耗的影响是非常大的,但通过美工的精修,可以让欧洲的头模拟合亚洲人。

4D 扫描主要是采集 3D 头模的时序数据,这里我们对比了目前业界顶尖的 4D 扫描方案,即:美国Di4D的公司,它是 Omniverse 4D 采集方案的供应商。
4D 采集需要在采集 3D 头模拓扑的同时去持续捕捉模特说话的细微面部变化。在保证效果的前提下,我们选择了更经济、更契合小布的方案。
- 在扫描范围层面,Omniverse 更注重全尺寸的头部,小布自研方案更聚焦面部区域。
- Omniverse 使用了 100 多台点阵相机来构建模特的全尺寸头模。小布方案使用了 9 台左右。我们将扫描出的点,将其拟合在开源头模上面,这样就可以专注在面部正面。节省了大量数据处理的时间和工作。
- Omniverse 的全尺寸头部重建效果好,基本保留了被重建者的全部特点,但设备的成本高昂,其中硬件的调试和维护、头模的制作周期都很长。而小布自研方案,聚焦快速实现效果,只采集面部的特征,然后通过焊接的方式拼接到开源头模上,从而构建起全尺寸头部重建数据。
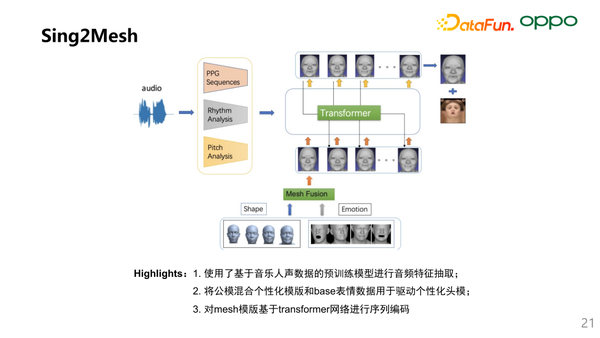
我们也基于 Mesh 的方案,开发了 Sing2Mesh 的架构:
(1)使用了基于音乐人声数据的预训练模型进行音频特征抽取
(2)因为目前大部分数据还是基于公模,我们采集到的数据更多用于Fine-Tuning。我们也参考了 Nvidia 的情感化的编码方案,使用了Mesh融合的架构,将公模混合个性化模板并与 Base 表情数据用于驱动个性化头模
(3)对 Mesh 模板使用了 Transformer 网络进行序列编码
这个架构主要是利用了小布的数据优势,并提升个性化头模的表征能力,和语言特征的鲁棒性。
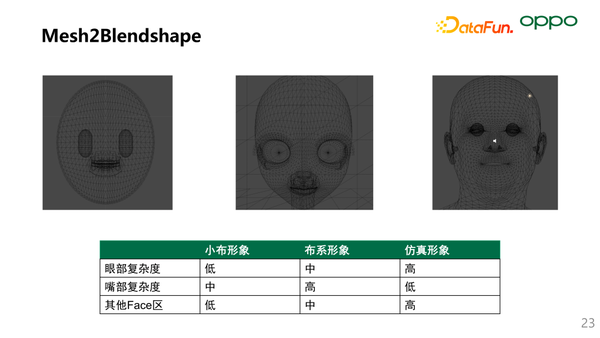
前面讲了 Mesh 和 BlendShape 的驱动在小布的方案落地,两种方案也都各有优缺点。小布也一直探索将 Mesh 和 BlendShape 的结合,这里对比了小布几种形象在 Mesh 各区的复杂度:从眼部、嘴部和其它面部区域进行对比。
- 在眼部区域:仿真形象的复杂度很高,主要体现在眼球上。对真人来说眼睛是很重要的。俗话说,眼睛是心灵的窗户。在做超仿真和仿真的时候,如果眼睛能够驱动的很好,眼睛的材质做的非常好,就成功了一大半。小布、布美美和布系形象因为眼部绑定的 BlendShape 数量的差异,复杂度有高有低。
- 在嘴部区域:按理来说,仿真的复杂度是最高的。但因为 Mesh 是实时计算,反而整个复杂度是最低的。而小布和布美美因为是 BlendShape 的驱动,区域绑定了很多 BlendShape,导致整个区域的复杂度较高。
- 其它的面部区域:因为小布和布美美是 BlendShape 驱动,复杂度根据 BlendShape 的数目决定的,该区域复杂度一般相对较小。仿真形象该区域个性化程度和复杂度都较高,同时个性化数据较难表征。
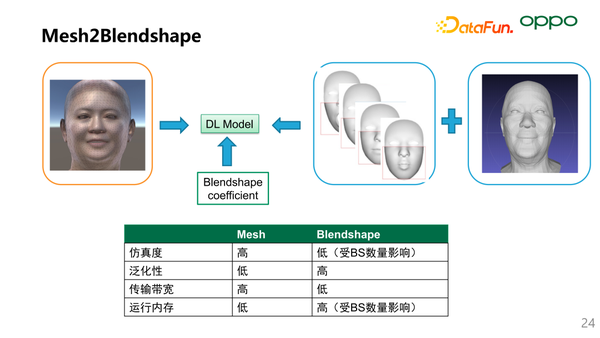
接下来对比一下 BlendShape 和 Mesh 驱动的优劣。
- 从仿真度来说,Mesh 的仿真度最高,当然 BlendShape 也可以达到很高的仿真度。有的公司可以把 BlendShape 拆到 500-1000 的数量,此时 BlendShape 的仿真度也是非常高的。
- 从泛化性能来看,因为 Mesh 是形象绑定,因此 Mesh 的泛化型低;BlendShape 是目前通用的行业标准,类似于 BlendShape 的“Look Right”,在任何体系下都是眼睛向右看的体现。
- 传输带宽这边,以上面的形象为例子,Mesh 需要传输 5000*3 的点位实时位移的数据;而 BlendShape 驱动只需传输 60-100 的 Blendshape 权重系数。
- 为提升表现力,需要增加 Blendshape 数目,但绑定 BlendShape 过多也会引起运行内存的过大,而 Mesh 在较少的面片数和点数上依然有很强的表现力。
同时我们可以设计一个深度学习模型,将Mesh和BlendShape进行转换,实现Mesh到BS系数的输出。从而实现两者优势互补。
--
04/领域现状与待解决问题

最后说一下领域现状和待解决的问题。上面的三张图分别代表了数字人建模、渲染和驱动的流程。
- 建模环节:4D 采集成本高昂,且牙齿、眼球等无法直接扫描,同时目前美工参与度较高。如果构建大规模数据库,需要大量的美术人力和模特。建模的流程化和流水线也需要进一步完善,以期大规模减少研发成本。
- 渲染环节:需要技术美工的参与以解决光照、反射等。目前通过算法拟合的 UV 或光照等效果与美工渲染的效果还有差距,特别是在人物运动的场景中。同时高质量的渲染与端侧设备的性能存在相互制约,如何进行端侧高质量渲染需要进一步研究。
- 驱动环节:目前业界语音面部驱动更多集中在嘴部肌肉群,带情绪化的全面部驱动还不够完善。此外,算法的评价客观指标稍显不足,如何让指标更多地反映自然顺滑度和拟人度,克服恐怖谷的效应还有待研究。同时,面部、表情、身体目前是独立的模块,缺乏整体协调的联动。
--
05/Q&A环节
Q1:唇形精度是如何评价的?
A1:目前中文数据集比较少,更多的是各个公司自己采集数据的。然后是通过人工评价的方式,类似 MOS 指标这类。
Q2:这方面的研究有公开的数据吗?
A2:基于 Flame 头模有不少机构开放有的 4D 采集数据,不过大部分是基于英文,中文的数据目前还很少。
Q3:视频号的数据,Mesh 可以编辑吗?
A3:可以。算法可以编辑,手工可以基于美工在 Maya、3Ds Max 上可以编辑。
Q4:动作是如何实现的?
A4:通过动捕设备的采集一些常见的动作库。
今天的分享就到这里,谢谢大家。
分享嘉宾

唐涔轩|OPPO小布助手 高级算法工程师
DataFun新媒体矩阵

关于DataFun
专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。