pypider抓取动态数据(豆瓣影视)
首先我们安装pyspider
我们在命令行里输入
pip install pyspider安装完成后,我们在命令行里输入
pyspider all这样我们就启动了pyspider

我们在浏览器中输入
127.0.0.1/5000
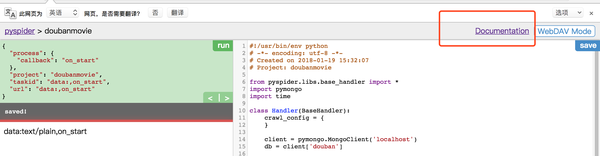
这样我们的pyspider 的webUI界面就打开了,
点击右上角的create 我们创建一个项目
然后我们写个项目名,点击创建即可

这时我们就进入到我们pyspider爬虫的编辑界面

这次我们要爬取的是豆瓣电影中的中国影片
首先我们进入到豆瓣影视的分类页面
https://movie.douban.com/tag/#/我们选择电影和中国大陆

这时下面就会自动加载出20个按热度排序的中国电影
这时我们打开Chrome浏览器的开发模式(右键选择检查)
点选下图的红色框部分,然后刷新页面

这时网页上动态加载的20个影片数据就全部出现了。并且是已json格式存储的

这时我们点选headers 选取红框中的url,这个url 就是我们真正要爬取的url

我们把这个url 复制到pyspider 的 start_url 中


这时我们改下下面的 index_page
只写入一行代码就行
return response.json[data]其他的后面的代码删除即可
然后点选右上角的存储按钮

接下来我们点选左边栏里的run按钮,运行我们的爬虫代码,这时下面的follows 会出现一个1.

我们点选follows,然后会出现我们请求的网页url

然后点选连接右边的小三角,就会出现爬取的结果

这样我们想要抓取的数据就出现了。接下来我们点选上面的pyspider 返回pyspider的爬虫控制界面


这时我们把status 调整成running 然后在点后面的run按钮就可运行我们的爬虫了

点完运行后,我们可以点击后面的ACTIVE 查看爬虫的运行状态


然后我们还可以点选后面的results按钮,

这时我们就会看到我们爬取的数据,点选右上角的 json 或csv 我们就可以把爬取的数据存储成json 和CSV

这样我们就用pyspider 爬取了一个动态加载的网页,是不是很简单。
pyspider 的更多操作我们可以去官网查看文档。
我们只要在pyspider的开发界面点击document就能进入官方文档界面。